导语:AI大模型训练的并行计算特性带来大量通信开销,使得网络成为制约训练效率的关键因素,无损网络成为刚需,具体表现为零丢包、高吞吐大带宽、稳定低时延以及超大规模组网。
随着ChatGPT横空出世,人工智能(AI)技术在短时间内呈现“涌现”态势,并成为推动社会进步的关键力量。AI技术的广泛应用给我们的生活和工作带来了巨大的改变,而这一切的背后离不开算力基础设施的支持。AI训练任务以及推理应用对算力有着高性能、大规模并行、低时延互联的要求,导致对计算、存储、互联网络有了不同于通用计算的要求,同时对算力聚合的要求也引发了基础设施管理平台的创新(见图1)。
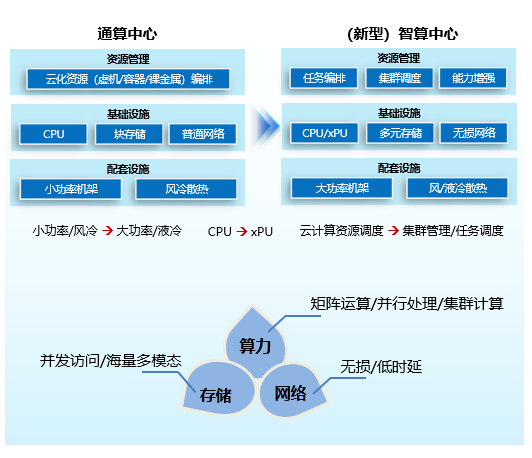
图1 智算中心创新架构
AI芯片
除了大模型训推有高性能矩阵运算的要求之外,大模型参数量越大对内存容量的需求越大,同时多颗AI芯片间的大量数据交互也带来了对互联总线高带宽、低时延的要求。因此,算力、显存以及互联总线形成了对AI芯片的三大能力要求。
算力方面,由于人工智能采用基于多层神经网络的机器学习技术,需要对大量数据进行矩阵运算,例如矩阵乘法、卷积、激活函数等。传统CPU以复杂数据流程见长,为此将更多的空间让渡给了控制单元和缓存单元,计算单元只占25%的空间,一般只有几十个算术逻辑单元(ALU),处理这些并行化和向量化运算的效率不高。而处理图像和图形相关运算的GPU计算单元占90%的空间,高达几千的ALU适合对密集数据进行并行处理。在2017年后,主流AI芯片厂家发布专门针对矩阵运算加速的AI GPU(GPGPU,general purpose computing on GPU),为大模型训练提供了更高的计算性能。除硬件之外,GPU厂家通常会提供相应的开发平台(如NVIDIA CUDA),它使得开发者能够直接使用GPU进行编程和优化,充分发挥GPU的计算能力。
显存方面,Transformer类模型参数量按照平均每两年翻240倍的速度增长,与之相比,AI内存容量仅以每两年翻2倍的速率增长,已经远远不能匹配大模型增长速率。为解决该问题,内存统一寻址的“超级节点”是目前比较可行的方案,如:定制AI服务器,通过高速互联技术组成1个超级节点(包含256颗GPU和256颗CPU),支持GPU和CPU之间的内存统一寻址,内存容量可以提升230倍。此外,AI芯片内采用计算和存储分离的冯·诺依曼架构,芯片60%~90%的能量消耗在数据搬移过程中。按照H800的最大功耗700W的60%来估算,数据搬移消耗了420W。为解决该问题,存算一体技术将内存与计算完全融合,避免数据搬移,大幅提升了能效。
互联总线方面,大模型3D并行拆分后,带来了芯片间数据传输的要求。其中数据传输量最大的张量并行(TP),在传输时间中的占比超90%。有测试数据表明,使用同样数量的服务器训练GPT-3,采用NVLink相比PCIE,一个Micro-batch在相邻GPU之间的传输时间从246.1ms降低到 78.7ms,整体训练时间从40.6天降低到22.8天,因此互联总线的带宽成为关键。
智算存储
在大模型开发端到端的多个环节中,都对存储提出了创新需求。具体包括:
多元存储:视频、图像、语音等多模态数据集带来块、文件、对象以及大数据等多元存储以及协议互通的要求;
海量存储:为保证大模型训练的精准性,数据集通常为参数量的2~3倍,在当前大模型从千亿到万亿飞速发展的时代,存储规模是一个重要的指标;
并发高性能:大模型并行训练场景下,多个训练节点需要同时读取数据集。在训练过程中,训练节点需要定时保存检查点(checkpoint)以保障系统的断点续训能力。这些读写操作的高性能能够大大提升大模型训练的效率。
因此,作为智算存储,首先需要提供多元数据存储能力以及块(iSCSI)/文件(NAS)/对象(S3)/大数据(HDFS)多协议互通能力。可通过软硬件综合调优来提升性能,硬件加速手段包括:通过DPU卸载存储接口协议以及去重/压缩/安全等操作,数据按热度自动分级及分区存储;软件调优手段包括分布式缓存、并行文件访问系统/私有客户端等。同时,采用NFS over RDMA以及GPU直接存储(GDS)技术也能够大大降低数据访问的时延。
无损网络
AI大模型训练的并行计算特性带来大量通信开销,使得网络成为制约训练效率的关键因素,无损网络成为刚需,具体表现为零丢包、高吞吐大带宽、稳定低时延以及超大规模组网。
目前的无损网络协议主要分为英伟达的IB与RoCE两大类。IB网络最初为高性能计算(HPC)设计,具备低延迟高带宽、SDN化拓扑管理、拓扑组网丰富以及转发效率高的优势,但存在产业链封闭的问题。RoCE为统一承载网络设计,具备高带宽/高弹性组网,对云化服务支持较好以及生态开放的优势,是国产化的必选之路。但是在网络性能和技术成熟度方面不如IB,需要结合芯片进一步优化时延。
传统网络拥塞和流量控制算法端侧和网侧独立,网络仅提供粗颗粒度的拥塞标记信息,很难确保网络高吞吐满负荷场景下不出现拥塞、丢包以及排队时延。因此需要端网协同实现精准、快速的拥塞控制和流量调度算法,进一步强化网络性能。
在网络拓扑方面,Fat-Tree CLOS和Torus轨道多平面拓扑为当前两种主流形态,从组网设计上解决网络拥塞问题。Fat-Tree CLOS网络基于传统树型网络增强,采用上下行带宽1:1低收敛比,保障任意两个节点间无阻塞路径;Torus轨道多平面网络将不同服务器相同位置GPU连接到同一组交换机,构成一个轨道平面。同时,服务器不同位置GPU连接到不同交换机,形成多个轨道平面。
资源任务调度平台
和通用算力资源管理平台通过虚拟云化技术将资源分发给多个租户不同,智算场景更强调的是算力聚合,即在AI任务训练中,可能同时运行数百个任务和上千个节点。通过任务调度平台,可以将执行的任务与可用资源进行最佳匹配,从而最小化任务在队列中等待的时间长度,最大化任务并行量,获得最优资源利用率。目前主流的调度系统有Slurm、Kubernetes两种。
Slurm主要应用于HPC场景下的任务调度,已经被世界范围内的超级计算机(包括天河等)和计算机群广泛采用;而Kubernetes作为容器编排平台,用于调度以及自动部署、管理和扩展容器化应用。目前Kubernetes和更广泛的容器生态系统逐渐成熟,正在形成一个通用的计算平台和生态系统。
在AI任务调度场景下,Slurm和Kubernetes面对着不同的挑战:深度学习工作负载的特征与HPC工作负载的特征非常相似,因此可以使用HPC任务调度器Slurm来管理其机器学习集群。但是,Slurm不是围绕容器开发的机器学习生态系统的一部分,因此很难将Kubeflow等AI平台集成到此类环境中。此外,Slurm使用较为复杂,维护难度大;另一方面,Kubernetes更易于使用,并与常见的机器学习框架集成,越来越多的企业和学术机构在他们的大模型训练中使用 Kubernetes。但是使用Kubernetes调度GPU资源时会遇到资源闲置时间过长,导致的集群平均利用率低(约为20%)、资源调度只能整卡调度,不能切分或按照卡的类型调度、不能进行任务排队等问题。
部署场景
由于基础大模型预训练、行业大模型精调以及客户场景大模型微调对算力特征及部署位置的要求均不同,结合运营商算力网络DC层次化分布的架构,智算中心部署也呈现枢纽大模型训练中心、省份训推融合资源池、边缘训推一体机三级部署模式(见图2)。

图2 智算中心层次化部署模式
当前,智算已经成为国家竞争的关键技术方向,运营商肩负着提升智算关键软硬件技术创新能力及智算基础设施建设的使命。中兴通讯拥有从IDC、芯片、服务器、存储、数通等基础设施到资源管理平台的全系列产品,结合在电信、政企领域的丰富经验,将助力运营商在智算技术创新及建设中大展宏图。

