GPU-based Hardware Acceleration Better Meets New Requirements for VoLTE and 5G Voice
Time:2019-02-16
Along with the continuous evolution of communication network to the cloud native architecture, SBC virtualization has become the industry consensus. SBC virtualization has the following characteristics:
It adapts to the "new normal state" of the development of communication network. In recent years, operators have been facing the dilemma of continuous decline in voice service tariffs and shrinking of operating revenue. To reduce construction and O&M costs and support the rapid deployment of services on demand, it is urgent to achieve resource concentration and sharing. Virtualization, which is the mainstream evolution strategy of telecommunication networks, is increasingly valued by the industry.
It has the advantages of unified/general hardware, distributed software, and on-demand resource allocation. The virtualized network elements can run on a common hardware platform to implement hardware and software decoupling of traditional telecommunication functions; they support hardware resource sharing and achieve maximum uniformity of CT/IT hardware; the media plane can flexibly apply for resources according to business development to effectively improve the network resource utilization.
The overall cost of the virtualized SBC hardware is lower than that of the physical SBC. The procurement cost and use cost (power consumption) of virtualized SBC hardware is about 1.2 times that of traditional SBC hardware, but the overall cost supports elastic scalability. According to statistics, the average resource utilization rate in 24 hours is about 63.3%, so the comprehensive cost is only 75%-80% of the latter.
However, the existing CPU-based virtualized SBC has limited TC capabilities and cannot meet the needs of large-scale access users. This drawback severely restricts the applications of virtualized SBC. To solve this problem, ZTE complies with the development trend of virtualization technology, creatively adopts the heterogeneous acceleration method, introduces the virtualized SBC (hereinafter referred to as vSBC) architecture based on CPU and GPU, and fully utilizes GPU hardware capabilities to effectively overcome the “bottleneck” of insufficient TC capabilities and lay the foundation for the popularity of vSBC.
Description of the GPU acceleration methods
A typical SBC network element integrates three physical units: signaling processing, media processing, and TC transcoding. Specifically, it includes dozens of media processing and corresponding signaling control functions such as user access, call processing, eSRVCC handover, emergency call, inter-network communication, and WebRTC.
Among these functions, TC transcoding is the most important “big element” for resource consumption, which will occupy more than half of the system resources, so hardware acceleration technology is essential. However, in the face of such a wide variety of demands, it is difficult to satisfy them only by relying on the CPU, and it is necessary to support them well through the linkage between the CPU and the GPU.
In general, the CPU of a virtualized network is precious. Therefore, it is the best choice to allocate services such as TC, which have complex computational logic and frequent algorithm changes, to the acceleration hardware such as GPU/FPGA. For forwarding services with low power, high forwarding, low latency, simple computational logic, and small algorithm changes, hardware acceleration is not needed.
The system architecture of ZTE vSBC is shown in Figure 1.

Figure 1 GPU-based Hardware Acceleration System Architecture
ZTE vSBC adopts Nvidia's general GPU series cards, which have the features of general hardware, common API, and shareability. All the vendors can share the system through an open interface.
The GPU series cards adopt the PCIe G3 hardware interface and the CUDA API general software interface. They have features such as many cores (more than 3,000 cores), high frequency, and few logical computing units. They can support virtualization and multi-vendor multi-application sharing. Its maximum power consumption of each card is only 250W, and its size is PCIe full-height full-length. As they adopt the fan cooling mode, these cards are suitable for massive parallel computing applications such as TC and can also be used in scenarios such as MEC, video, big data, encryption, compression and AI.
With respect to hardware, the GPU series cards can be plugged into general rack servers; with respect to software, the GPU series cards can support OS environments such as OpenStack P/Q version, Linux and KVM.
ZTE vSBC has absolute advantages in terms of quantity, power consumption, space and cost. By adopting the GPU-based TC hardware acceleration method, the overall cost of ZTE vSBC is reduced by more than 50% compared with the CPU-based vSBC. At the same time, the number of servers is reduced and the procurement complexity can be significantly reduced.
According to the general VoLTE traffic model (typically configured with 4 million users), the comparison of the number of TC resources and machine resources (using rack servers) required by these two methods (referred to as GPU and CPU respectively) is shown in Figure 2.

Figure 2 Contrast of Resources Necessary for GPU and CPU
ZTE vSBC basically has a “zero” requirement for the construction and management of resource pools, and it can also help increase GPU card resources or build accelerated resource pools as needed.
ZTE vSBC has added accelerators and virtual accelerator resource modules. When a host/blade with accelerated hardware is found, NFVI reports the corresponding capability to VIM, and VIM manages all hosts/blades (including resource configuration, resource allocation, and resources release, information management, and performance management) to accelerate the virtualization of resources.
There are two types of resource pool deployment methods: One is to the separation of acceleration hardware from general hardware, and the other is to the integration of acceleration hardware and general hardware. Both methods are applicable to different application scenarios, as shown in Figure 3.
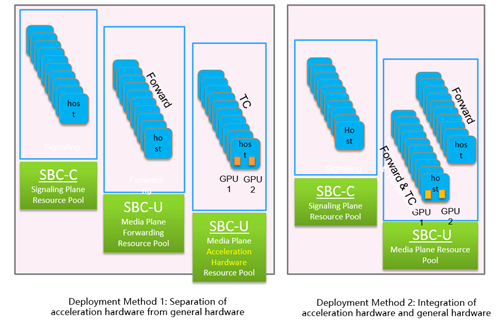
Figure 3 2 Methods of Deploying the Resource Pool
Because signaling processing and media processing have different sensitivity to latency, they are generally deployed in different resource pools.
Contrast of two Acceleration Methods
In summary, compared with the traditional CPU-based acceleration method, the GPU-based heterogeneous acceleration method is also a mature general solution. Their forwarding acceleration methods are the same, and the differences with respect to flexibility and O&M are not large. The key difference is that the number of servers and total cost of the latter is only about half of the former. Therefore, not only the network performance is improved, but also the cost performance is better. Meanwhile, the procurement complexity is also significantly reduced.
To visually compare them, the table below briefly lists the main similarities and differences between the two methods.

Conclusion
So far, ZTE is the only vendor in the industry to support GPU-based hardware acceleration, and it has an undisputed leading position in this field.
Through this innovative method, the TC performance of ZTE vSBC has been significantly improved, which can better meet the virtualization requirements of VoLTE and future 5G voice and help operators provide users with higher performance and better services.

